Resumen del proyecto
Análisis de calidad de bug reports de Mozilla Bugzilla. El objetivo es predecir el puntaje
CTQRS (13–17) de un reporte usando features del texto y metadatos del bug.
Pipeline de procesamiento — 17 pasos
Desde los archivos originales CSV/Excel hasta los datasets curados listos para modelado.
Visualizaciones por dataset
25 gráficos descriptivos generados por visualizaciones/visualizaciones.py.
Filtrá por dataset y tipo de gráfico, click en cualquier imagen para ampliar.
Análisis de Outliers — IQR Tukey
Fences 1.5x (leves) y 3x (extremos) sobre todas las columnas numéricas de los 4 datasets.
Conclusión: todos los outliers son REALES — distribución ley de potencias en actividad y conteos.
Porcentaje de outliers por columna
Barras agrupadas: leves (1.5x IQR) vs. extremos (3x IQR). Generación interactiva equivalente al PNG de resumen.
Imágenes estáticas del análisis
Acciones recomendadas
Framing supervisado
Análisis de las 7 preguntas de modelado con evidencia estadística concreta (Paso 16 del pipeline).
Distribución de Total Score (variable objetivo)
Score 13–17 · Clasificación multiclase ordinal · Dataset desbalanceado.
El score en amarillo es la clase dominante.
Correlación de Pearson — variables numéricas
IDs excluidos. Rojo = correlación negativa, azul = positiva.
Hallazgo clave: Comment Count correlaciona negativamente con Total Score (r ≈ −0.13).
7 preguntas de framing supervisado
Hipótesis del documento académico
EDA descriptivo de 3 hipótesis formales con cadenas causales (Paso 17).
Los veredictos se computan dinámicamente desde los datos curados.
Cadena: Bugs Filed → Total Score → Comment Count
Los colaboradores con mayor experiencia (más bugs reportados) producen reportes de mayor
calidad CTQRS, lo que reduce la ambigüedad y el debate posterior (Comment Count bajo).
Score CTQRS medio por cuartil de experiencia (Bugs Filed)
Gradiente positivo Q1→Q4 confirmaría H1.A.
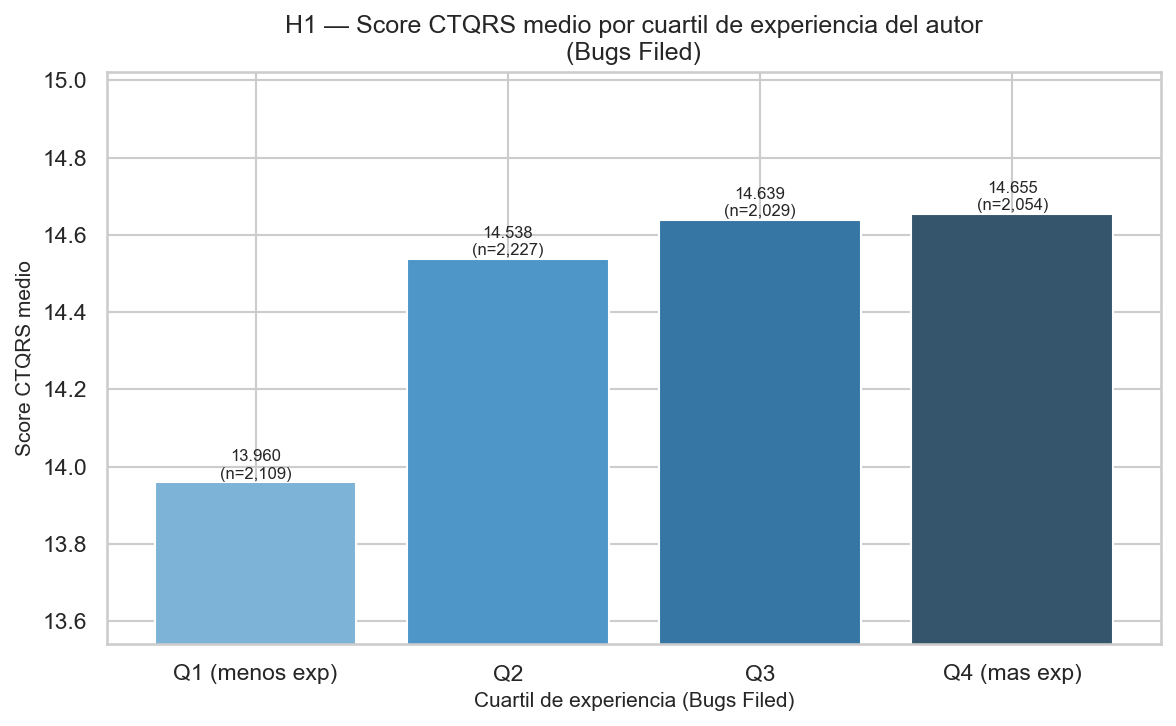
Imagen estática — hipotesis_iniciales.py
H1.B — Total Score → Comment Count medio
Mayor score (mejor reporte) debería corresponder a menos comentarios (H1.B).
H1.C — Top 10% vs Bottom 10% de experiencia
Comparativa de score y Comment Count entre autores extremos.
Cadena: Severity alta → Score bajo → Priority dispersa → días de resolución altos
Los bugs de alta severidad (blocker/critical) tienen reportes de menor calidad CTQRS,
lo que provoca prioridades desalineadas y retrasos en la resolución.
Score CTQRS medio por nivel de severidad
Si blocker/S1 tiene el score más bajo, la paradoja se confirma (H2.A).
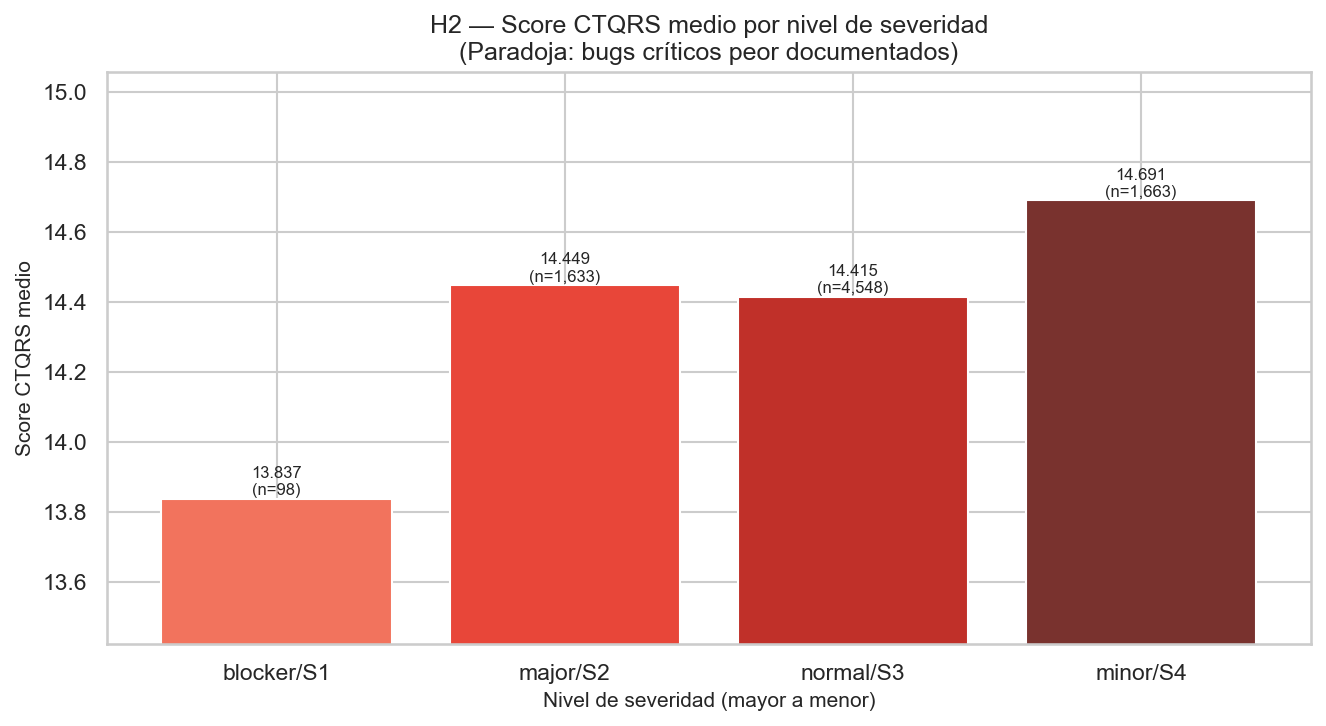
Imagen estática — hipotesis_iniciales.py
H2.B — Crosstab Severity × Priority (bugs de alta severidad)
% de bugs de cada severidad que reciben cada nivel de prioridad.
H2.C — Mediana de días de resolución por Severity × Score bin
Bugs con baja calidad (score bajo) y baja severidad deberían tardar más en resolverse.
Cadena: n_dependencias → Comment Count alto → CTQRS predice Priority mejor que Severity
Los bugs con más dependencias (Blocks, Depends On, Duplicates, Regressions) generan más debate
técnico. Un CTQRS elevado predice mejor la prioridad final que la severidad sola.
Comment Count medio por cuartil de dependencias totales
Gradiente positivo Q1→Q4 confirmaría H3.B.
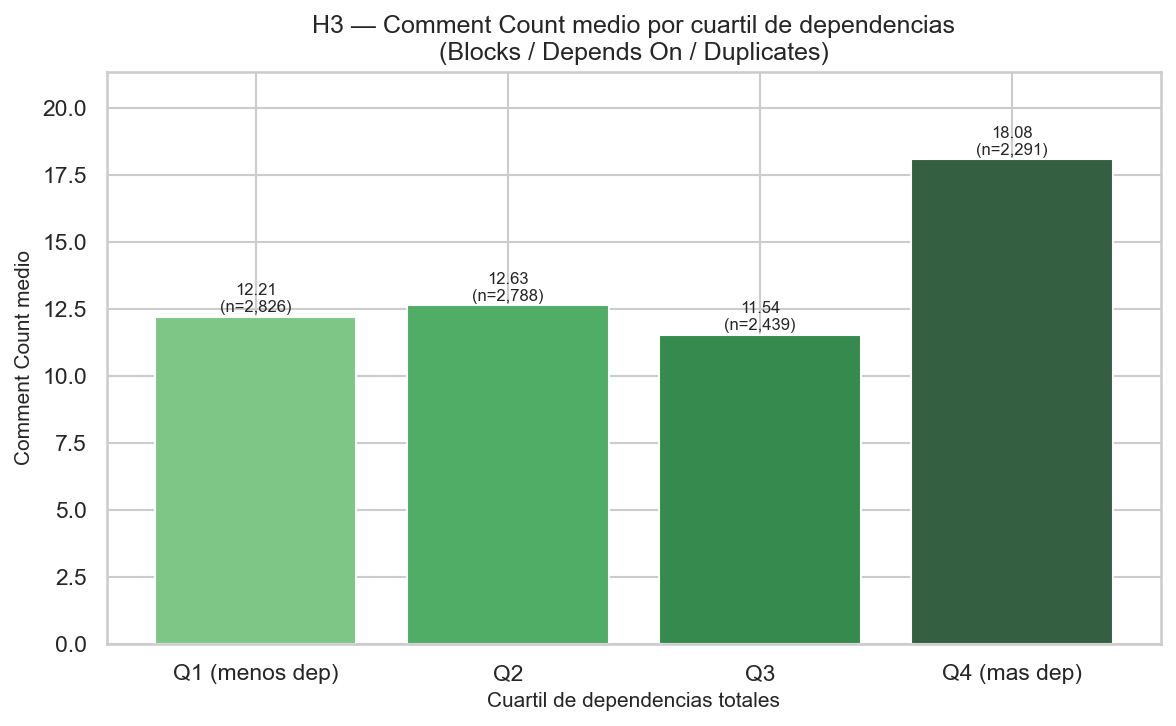
Imagen estática — hipotesis_iniciales.py
H3.A — Distribución de dependencias por tipo
% de bugs con al menos una dependencia de cada tipo.
H3.D — Perfiles de bugs con Priority P1
Perfil B (baja severidad + bloqueos) ≥ 5% de P1 indica que bloqueos influyen en priorización.